Improving user experience : AB Testing changes
We will be using statistical tools to validate improvements in the retention rate of our app
We will be using statistical tools to validate improvements in the retention rate of our app
Data source : https://www.kaggle.com/yufengsui/mobile-games-ab-testing
Imagine we have developed a mobile application and we are want to improve the retention of our app,it is a mobile game where they encounter gates that forces them to wait a certain amount of time, or make an in-app purchase to progress. This is a way to encourage user spending and also to increase the usage and retention of the game, but where should the gate be placed?
The users are divided in two groups:
We want to find if it is better to place the gate at level 30 or level 40, we do this by recording:
import pandas as pd
import numpy as np
import pymc3 as pm
import plotly.graph_objects as go
import arviz as az
data = pd.read_csv("cookie_cats.csv",index_col = 0)
display(data.head(5))
| version | sum_gamerounds | retention_1 | retention_7 | |
|---|---|---|---|---|
| userid | ||||
| 116 | gate_30 | 3 | False | False |
| 337 | gate_30 | 38 | True | False |
| 377 | gate_40 | 165 | True | False |
| 483 | gate_40 | 1 | False | False |
| 488 | gate_40 | 179 | True | True |
Let’s check for missing data:
display("Missing values : "+ str(sum(data.isnull().values)))
'Missing values : [0 0 0 0]'
Split the dataset into A and B groups
a = data[data["version"] == "gate_30"]
b = data[data["version"] == "gate_40"]
To find out the group that has better retention we use AB testing to find if there is a statistically significant difference between the two groups, in particular, we want to consider the following random variables:
\[P(\textrm{user coming back 1 day after installation} \mid \textrm{gate at 30})\] \[P(\textrm{user coming back 1 day after installation} \mid \textrm{gate at 40})\]In short:
\[P(X \mid A)\textrm{ ~ Bernoulli } (p_A)\] \[P(X \mid B)\textrm{ ~ Bernoulli } (p_B)\]Where X is the event “user coming back 1 day after installation” and can take a true or false value.
What we are really interested in is \(p_A\) and \(p_B\) which are the probabilities of the user coming back being true:
\[\textrm{Retention Rate}_A = P(X = 1 \mid A) = p_A\] \[\textrm{Retention Rate}_B = P(X = 1 \mid B) = p_B\]\(p_A\) and \(p_B\) are what we call the Retention Rate of putting the gate at level 30 and putting the gate at level 40
To estimate \(p_A\) and \(p_B\) we will use the Bayesian inference with PyMC3 which is a python package for Bayesian statistical modeling and probabilistic machine learning which focuses on advanced Markov chain Monte Carlo (https://docs.pymc.io/).
We want to test with a significance level = 0.05 if the retention rate of B is greater than group A, thus we test the null hypothesis that with:
\[D = p_B-p_A\] \[H_0 : D \leq 0\]Against the alternative hypothesis:
\[H_1 : D > 0\]We also want to calculate the relative change from group A to group B:
\[R = \frac{p_B-p_A}{p_A}\]with pm.Model():
a_p = pm.Beta("a_p",1,1)
b_p = pm.Beta("b_p",1,1)
a_bin = pm.Bernoulli("a bernoulli",p = a_p,observed = a["retention_1"])
b_bin = pm.Bernoulli("b bernoulli",p = b_p,observed = b["retention_1"])
difference = pm.Deterministic("1 day retention difference",b_p-a_p)
rel_difference = pm.Deterministic("1 day retention relative difference",(b_p-a_p)/a_p)
trace = pm.sample(10000, tune=1000, cores = 4)
pm.plot_density([trace.get_values("a_p"),trace.get_values("b_p")],credible_interval = 1.0,data_labels=["a_p","b_p"],shade=.8)
pm.plot_posterior(trace,var_names = ["1 day retention difference","1 day retention relative difference"],credible_interval = None,ref_val = 0,round_to = 6)
display(pm.summary(trace,credible_interval = 0.98)[["mean","sd","hpd_1%","hpd_99%"]])
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [b_p, a_p]
Sampling 4 chains, 0 divergences: 100%|██████████| 44000/44000 [01:39<00:00, 440.61draws/s]
| mean | sd | hpd_1% | hpd_99% | |
|---|---|---|---|---|
| a_p | 0.448 | 0.002 | 0.443 | 0.454 |
| b_p | 0.442 | 0.002 | 0.437 | 0.448 |
| 1 day retention difference | -0.006 | 0.003 | -0.014 | 0.002 |
| 1 day retention relative difference | -0.013 | 0.007 | -0.030 | 0.004 |
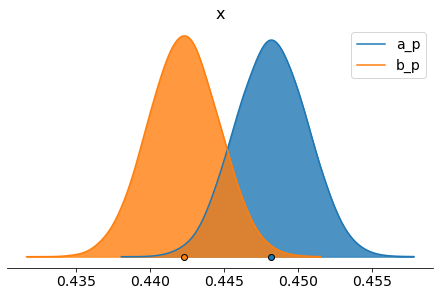
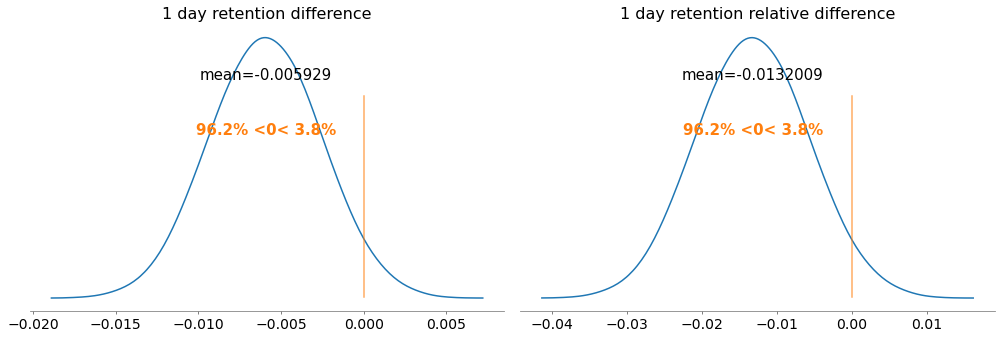
Here we can see that the probability of our null hypothesis being true is 96.2% (this is our p-value, bigger than our significance level of 5%), thus we can say that moving the gate to level 40 does not improve our 1 day retention, accepting the null hypothesis, with a mean decrease in retention rate of 0.5%, which is around 1.3% worse than leaving it at level 30
Now we apply the same reasoning written above to evaluate the change in the 7 days retention given the same null hypothesis and the same significance level
with pm.Model():
a_p = pm.Beta("a_p",1,1)
b_p = pm.Beta("b_p",1,1)
a_bin = pm.Bernoulli("a bernoulli",p = a_p,observed = a["retention_7"])
b_bin = pm.Bernoulli("b bernoulli",p = b_p,observed = b["retention_7"])
difference = pm.Deterministic("7 day retention difference",b_p-a_p)
rel_difference = pm.Deterministic("7 day retention relative difference",(b_p-a_p)/a_p)
trace = pm.sample(10000, tune=1000, cores = 4)
pm.plot_density([trace.get_values("a_p"),trace.get_values("b_p")],credible_interval = 1.0,data_labels=["a_p","b_p"],shade=.8)
pm.plot_posterior(trace,var_names = ["7 day retention difference","7 day retention relative difference"],credible_interval = None,ref_val = 0,round_to = 6)
display(pm.summary(trace,credible_interval = 0.98)[["mean","sd","hpd_1%","hpd_99%"]])
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [b_p, a_p]
Sampling 4 chains, 0 divergences: 100%|██████████| 44000/44000 [01:23<00:00, 524.56draws/s]
| mean | sd | hpd_1% | hpd_99% | |
|---|---|---|---|---|
| a_p | 0.190 | 0.002 | 0.186 | 0.195 |
| b_p | 0.182 | 0.002 | 0.178 | 0.186 |
| 7 day retention difference | -0.008 | 0.003 | -0.014 | -0.002 |
| 7 day retention relative difference | -0.043 | 0.013 | -0.075 | -0.012 |
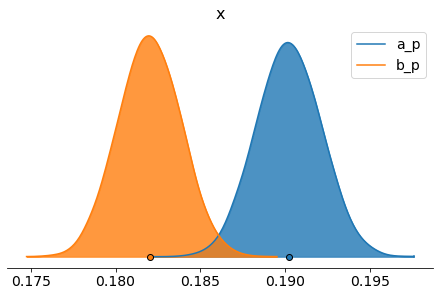
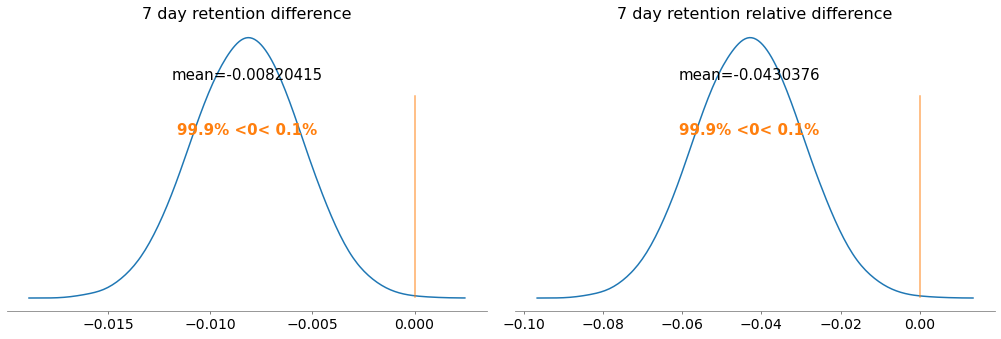
Here the evidence is even stronger, we have a p-value of 99.9%, much bigger than our 5% threshold, again we accept \(H_0\).
With a mean decrease in retention rate of around 0.8%, which is around 4.3% worse than leaving it at level 30, we conclude that moving the gate at level 40 does not improve our 7 days retention.
Now we want to test if there is a significant difference in the number of game-rounds played, given that we don’t know the distribution of the game-rounds played, we take a look at the histograms of the two groups:
fig = go.Figure(go.Histogram(x = a["sum_gamerounds"],histnorm="probability density",name = "Gate 30",nbinsx = 7000))
fig.add_trace(go.Histogram(x = b["sum_gamerounds"],histnorm="probability density",name = "Gate 40",nbinsx = 7000))
fig.update_traces(opacity=0.8)
fig.update_layout(barmode="stack",
title="Game rounds played histogram",
xaxis_title="Total game rounds played",
yaxis_title="Relative frequency",)
fig.show()
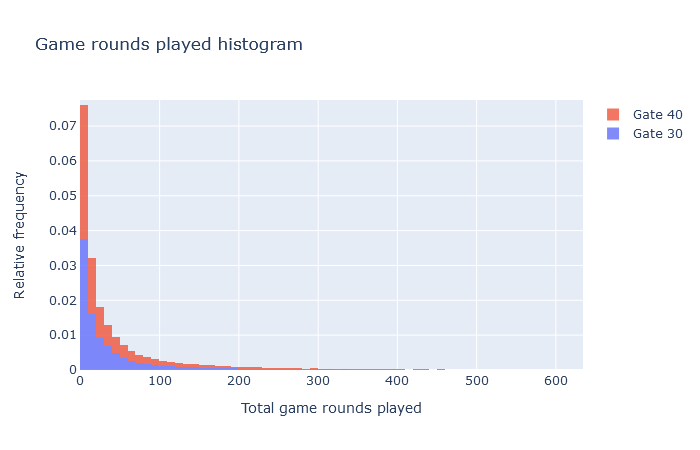
We model the number of game-rounds played as a negative binomial random variable X:
\[P(X \mid A) \textrm{ ~ NB }(μ_A,α_A)\] \[P(X \mid B) \textrm{ ~ NB }(μ_B,α_B)\]\(μ_A\) and \(μ_B\) are the means of the distributions and \(α_A\),\(α_B\) their shape parameters
We want to test the difference of the means between group B and A with a significance level of 0.05:
\[D = μ_B-μ_A\] \[H_0 \leq 0\] \[H_1 > 0\]And calculate relative change from A :
\[R = \frac{μ_B-μ_A}{μ_A}\]We choose an Exponential prior for \(μ_A\) and \(μ_B\)
with pm.Model():
a_mean = pm.Exponential("a mean",lam = 1/a["sum_gamerounds"].mean())
b_mean = pm.Exponential("b mean",lam = 1/b["sum_gamerounds"].mean())
a_alpha = pm.Gamma("a alpha",1,1)
b_alpha = pm.Gamma("b alpha",1,1)
a_distribution = pm.NegativeBinomial("a distrib",mu = a_mean,alpha = a_alpha)
b_distribution = pm.NegativeBinomial("b distrib",mu = b_mean,alpha = b_alpha)
a_gamma = pm.NegativeBinomial("a exp",mu = a_mean,alpha = a_alpha,observed = a["sum_gamerounds"])
b_gamma = pm.NegativeBinomial("b exp",mu = b_mean,alpha = b_alpha,observed = b["sum_gamerounds"])
difference = pm.Deterministic("mean gameround difference",b_mean-a_mean)
rel_difference = pm.Deterministic("mean gameround relative difference",(b_mean-a_mean)/a_mean)
trace = pm.sample(10000, tune=1000, cores = 4)
pm.plot_density([trace.get_values("a mean"),trace.get_values("b mean")],credible_interval = 1.0,data_labels=["a mean","b mean"],shade=.8)
pm.plot_density([trace.get_values("a distrib"),trace.get_values("b distrib")],data_labels=["a distrib","b distrib"],shade=.6)
pm.plot_posterior(trace,var_names = ["a distrib","b distrib"],credible_interval = None,round_to = 6)
pm.plot_posterior(trace,var_names = ["mean gameround difference","mean gameround relative difference"],credible_interval = None,ref_val = 0,round_to = 6)
display(pm.summary(trace,credible_interval = 0.98).loc[["a mean","b mean","mean gameround difference","mean gameround relative difference"]][["mean","sd","hpd_1%","hpd_99%"]])
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>NUTS: [b alpha, a alpha, b mean, a mean]
>CompoundStep
>>Metropolis: [b distrib]
>>Metropolis: [a distrib]
Sampling 4 chains, 0 divergences: 100%|██████████| 44000/44000 [18:12<00:00, 40.28draws/s]
The number of effective samples is smaller than 10% for some parameters.
| mean | sd | hpd_1% | hpd_99% | |
|---|---|---|---|---|
| a mean | 52.459 | 0.362 | 51.622 | 53.302 |
| b mean | 51.301 | 0.350 | 50.500 | 52.123 |
| mean gameround difference | -1.158 | 0.501 | -2.323 | -0.004 |
| mean gameround relative difference | -0.022 | 0.009 | -0.044 | -0.000 |
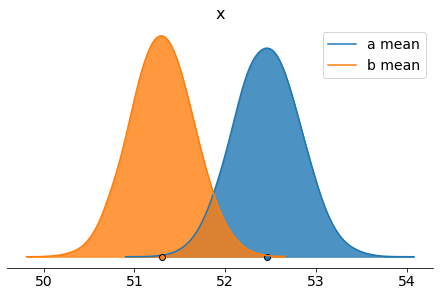
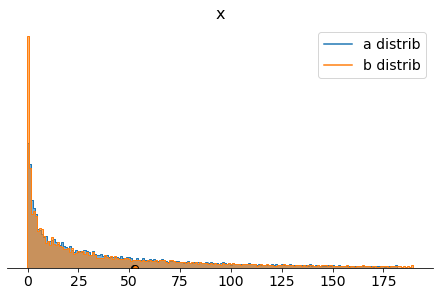
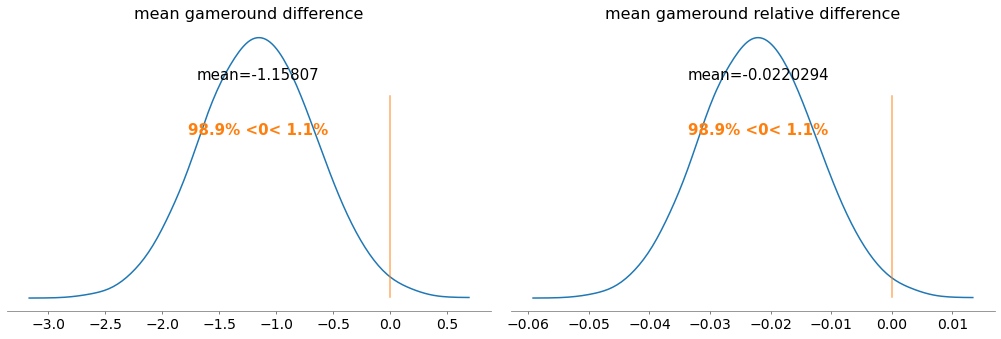
Again, same reasoning, the difference of means is around -1.16, 2.2% worse, p-value = 98.9%, bigger than our confidence level of 5% (let’s remember one more time that in order to refuse the null hypothesis the probability of the mean difference being less or equal than 0 must be less or equal than our confidence level).
We conclude that moving the gate does not improve the number of rounds played.
Given the data we collected and the effects of our decision on the indicators we analyzed, it is safe to say that moving the gate to level 40 worsens our 1 day and 7 days retention and the number of rounds played.
This can be explained in a well known phenomena in the entertainment industry called “hedonic treadmill”, by playing and generating a sense of happiness in the user, it needs more and more entertainment to keep the user at that state, otherwise, he will get bored.
By forcing the user to take a break earlier (with the gate mechanic we explained at the beginning at level 30 instead of 40), we avoid the user getting bored by the game and keep him coming back.
We will be using statistical tools to validate improvements in the retention rate of our app
We will analyze the sales data of the videogames market using the data about games with more than 100000 copies sold
In this post we will find out how to choose the best location for multiple capacitated facilities given a set of points of interest
In this post we will find out how to choose the best location for a single uncapacitated facility given a set of points of interest